A $1.3M token burn reveals the hidden rule: the critic must live outside the loop, or the loop grades its own homework and calls it done.
A $1.3M token burn reveals the hidden rule: the critic must live outside the loop, or the loop grades its own homework and calls it done.
Direct answer: An AI agent loop is useful when the agent can act, inspect a result, receive a clear signal, and try again inside a bounded lane. It turns into expensive slop when the task still depends on taste, hidden product context, or decisions outside the repo’s evidence.
Everyone wants the magic loop now.
One command. One spec file. One agent. The machine plans, builds, reviews itself, fixes itself, pushes again, keeps going, and returns with the finished thing while the human does something more glamorous than babysitting a terminal.
That is the dream version.
The useful version is smaller, more annoying, and equipped with a steering wheel.
In Greg Isenberg’s conversation with Ras Mic, the word “loop” gets pulled out of the hype fog and drawn as stick figures on a whiteboard. Mic’s opening promise is blunt: by the end, the viewer should know what a loop is, why people are excited, why it can be a terrible mistake “unless you have money to burn,” and where he actually uses one himself.
That distinction matters because most AI automation failure has the same shape. The agent looks busy, chooses a plausible direction, and stays plausible for too long.
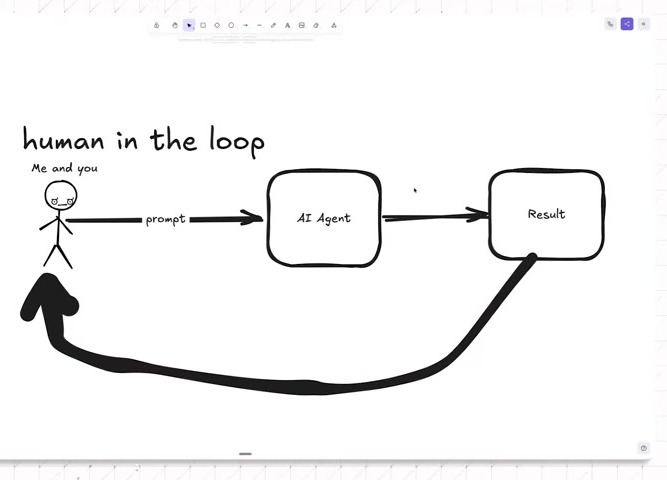
The conversation opens with the ordinary human-in-the-loop pattern. A person prompts an AI agent in Cursor, Claude, Codex, or another tool. The agent produces a result. The person looks at it, corrects course, and sends the next prompt. His examples are concrete builder tasks: build a landing page, add a feature, handle authentication, move to the backend.
That sounds boring because it is. It is also the version most builders can trust.
The whiteboard version is intentionally primitive: “me and you,” an AI agent, a result box, and arrows between them. The value is in the arrow that comes back. A result stops being a terminal artifact and becomes evidence for the next turn.
In the ordinary version, the human owns the comeback arrow. You see the result. You notice the missing context. You decide whether the agent should refactor, delete, test, rewrite, or stop.
In the agent-run version, the human fires once. The agent reads the result, judges it, feeds that judgment back into itself, and continues. The speakers name the recent versions directly: Ralph loops, Ralph Wiggum, and slash-goal style workflows. They are useful for prototypes and experiments. They are dangerous when the details matter and the token budget is real.
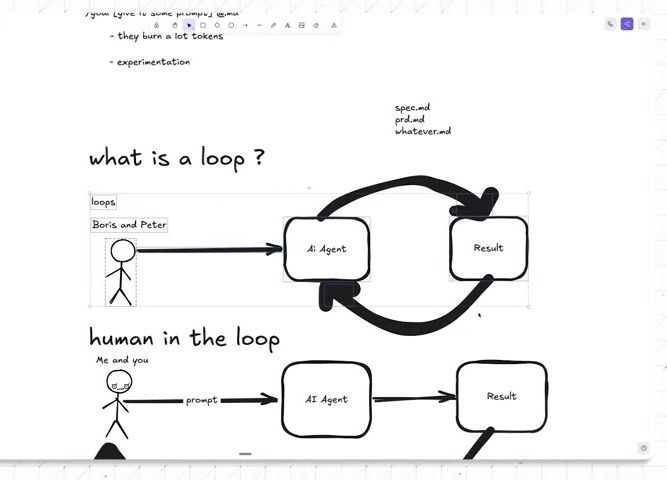
That small shift changes the whole risk profile.
A human-in-the-loop workflow is a bicycle with power assist. An autonomous agent loop is a car with the accelerator taped down and a note on the windshield that says “arrive at product-market fit.” The second one sounds exciting until you remember roads have turns.
The innovation lives in deciding what deserves to be looped.
The conversation gives the startup-builder version of the failure mode. Imagine hiring a brilliant developer, handing them a spec, and sending them away to build the whole product from written instructions alone.
A great developer can fill gaps. That is the problem.
Every product spec has missing choices. Should the landing page feel premium or scrappy? Is authentication a temporary demo shortcut or production infrastructure? Does the backend need boring reliability now or later? What should the product look like after the first user reacts badly?
A human engineer asks, pushes back, or makes a judgment from shared context. An agent loop often turns the blank space into a guess. Then it builds on the guess. Then it reviews the guessed artifact against the guessed plan. Then it spends more tokens defending the little world it just invented.
That is where the phrase earns its keep: the slop machine.
Slop here means output with the wrong relationship to reality. The UI may look fine. The prose may read fine. The agent produces enough surface area that progress looks visible, while the underlying decisions drift away from the human’s intent.
Cleanup costs more than the model bill.
A full-stack app built in the wrong direction has the social cost of a bad meeting and the technical cost of a bad migration. Someone has to read it, understand it, unwind it, rescue the good pieces, and restore trust in the workflow.
That is why token budget becomes a central warning. Mic says the builders praising wide-open loops often have unusual constraints: more access, more harnesses, more budget. He cites Peter burning $1.3 million worth of tokens in a month, then immediately softens the posture: loops have use cases, and the economics change for builders with ordinary budgets.
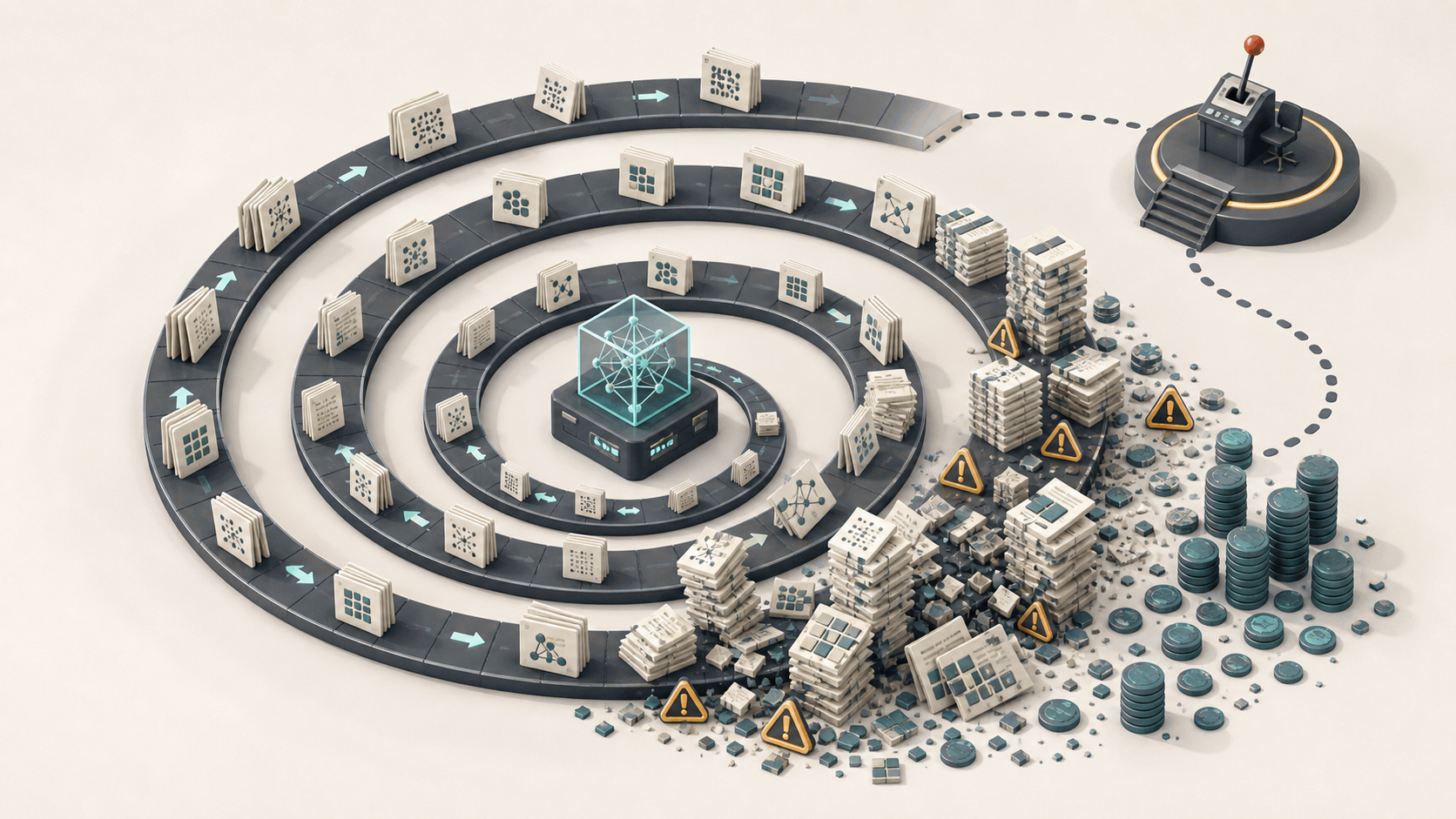
The colder rule: autonomy is economics before aesthetics.
There is one friendly case before code review: throwaway experimentation.
The conversation describes building an Among Us simulator for AI models because he wanted a benchmark around lying and impostor detection. The visual details were irrelevant. Product taste was irrelevant. He wanted the simulation and benchmark to work. In that case, telling the agent to go build the thing made sense because the goal was a crude working experiment rather than a polished product surface.
That is the first useful boundary.
When details are irrelevant, the loop can be loose.
If the details carry the product, the loop needs rails.
The practical version appears in code review.
Before the loop, the diagram is familiar. Code moves from Cursor to GitHub. A pull request waits for review. A human or review tool finds issues. Someone fixes them.
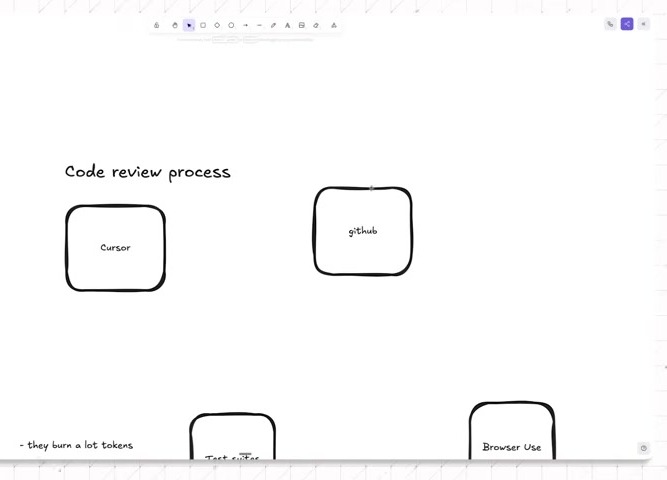
He adds the loop he actually runs: Cursor, GitHub, and Greptile.
He pushes AI-generated code to GitHub. Greptile reviews the pull request and produces feedback: missed issue, security concern, broken edge case. The key feature is the score out of five. Mic’s rule sends code live only once the score is greater than four out of five. If the review lands below that threshold, a skill he calls “Grep loop” sends the feedback back into Cursor. Cursor fixes the issues, pushes again, and the loop continues.
The stop rule is just as important as the score. The loop stops after five turns or when the PR reaches five out of five. Mic’s phrasing is simple: it is closed-off, goal-oriented, and driven by a feedback engine.
This works because code review has something open-ended app generation lacks: a scoring surface.
A scoring surface is any external signal the agent can act against instead of inventing the whole product vision. Tests pass or fail. A reviewer names a risky function. A PR gets a score. A security warning points to a line. The loop can chase those signals because the target is visible.
That is the whole difference. The agent improves an artifact against a defined critic instead of deciding what should exist.
Mic’s example also keeps itself humble. The code-review loop still breaks, especially when a change is larger than about 1,000 lines. At that size, the reviewer agent struggles to contextualize everything and five out of five slips out of reach. The fix is smaller PRs.
That detail is the whole philosophy in miniature.
Good loops make work smaller before they make it faster.
Mic’s whiteboard version is casual. The serious engineering literature has started arriving at the same shape.
Anthropic’s agent guidance argues that the most reliable agent systems tend to use simple, composable patterns rather than ornate autonomous frameworks. The important distinction is between workflows, where code routes the model through known steps, and agents, where the model chooses its own path through tools and feedback. That distinction matches the core tension in this piece: the more freedom the agent gets, the more the environment needs rails, observability, and a reason to trust the next turn. Anthropic, “Building effective agents”
OpenAI’s Agents SDK frames production agents as models wrapped in instructions, tools, handoffs, guardrails, and structured outputs. The boring nouns matter. A loop without guardrails is just recurrence. A loop with handoffs, tracing, and explicit output shape becomes inspectable infrastructure. OpenAI Agents SDK OpenAI tracing docs
LangGraph’s human-in-the-loop docs make the human checkpoint durable: an agent can pause, wait for approval, and resume from the checkpoint rather than replay the whole run. That is the grown-up version of “pull over often.” The point is not that a human clicks approve forever. The point is that the system treats approval as part of the runtime, not as a Slack message after the accident. LangChain HITL docs
Greptile’s own code-review framing also supports the same pattern. Its public docs describe an AI code-review agent that analyzes pull requests with repository context and returns summary, inline feedback, and suggested fixes. That is a critic surface. The loop only becomes useful when the critic has enough context to disagree with the writer. Greptile developer quick reference
My distillation from Mic’s code-review loop is a four-part test.
A useful loop has four parts:
1. A bounded artifact.
2. A critic with a stable rubric.
3. A turn limit.
4. A human stop condition.
Remove any one of those and the loop starts acting like a story generator.
A bounded artifact keeps the loop from expanding the battlefield. “Fix this PR until the reviewer score improves” is bounded. “Make the app better” is a fog machine.
A stable critic keeps the loop from grading its own homework. The critic can be a test suite, a code-review agent, a browser assertion, or a human review. The key is that the signal lives outside the writer agent’s immediate impulse.
A turn limit keeps the loop honest. Five tries is a loop. Unlimited retries is a belief system.
A human stop condition preserves taste. The machine can discover problems, propose fixes, and close obvious gaps. Product judgment still decides when the work has become too much, when a clever abstraction should be deleted, or when a technically correct answer violates the intent of the work.
The most practical point is modest. Loops are strongest when they are least dramatic.
The boring loop is the one that saves you.
It is tempting to treat human-in-the-loop as a temporary weakness. Today the human steers; tomorrow the model gets smarter; eventually the person disappears.
The better position is more precise. This is a June 9, 2026 judgment about present capability. Both speakers leave room for stronger autonomous loops later. Right now, the capability is unevenly distributed across task types.
Some work becomes autonomous as soon as the feedback gets formal enough. If a test can catch the failure, if a score can guide the edit, if the artifact is narrow, the human can move farther away.
Other work stays human-shaped because the feedback is social, strategic, or taste-based. A founder deciding what the product should become goes beyond known requirements. They are choosing among futures. The “correct” answer might depend on a customer call, a brand instinct, an unwritten fear, or a private constraint.
An agent can help expose those choices. It can draft options, simulate consequences, inspect code, generate prototypes, and find contradictions. The loop becomes dangerous when it converts that uncertainty into fake certainty.
Greg’s road-trip analogy lands because it brings the abstraction back to a body. A startup loop with zero feedback is like pressing go on full self-driving from Miami to Charleston. The halfway stop disappears. The cute diner on the side of the road disappears. The route keeps moving after reality offers a reason to change course. The train has left the station.
That is the right model for AI loops in product work.
Let the agent drive a stretch of highway. Make it pull over often. Look at the map yourself.
Before adding an agent loop to a workflow, ask five questions.
What artifact is the loop allowed to change?
If the answer is “the whole app,” narrow it. A PR, a page, a small benchmark, a browser-use task, or a bug reproduction is a better unit.
Who or what judges the result?
If the loop’s only judge is the same agent producing the work, add an outside critic. Use tests, a code-review agent, a browser-use check, a narrow SEO/page rubric, or human review.
Can the feedback be converted into an edit plan?
“Make it better” is weak feedback. “The reviewer found a security issue, a broken edge case, and a score below four out of five” is loop fuel.
How many turns are allowed?
A missing stop rule turns the loop into an anxiety machine. Pick a number. After five failed passes, the problem probably needs a human decision, a better critic, or a smaller scope.
What decision remains human-owned?
Name it before the loop starts. Shipping, merging, publishing, and changing product direction belong to the human unless the organization has explicitly delegated that authority.
These questions make the loop less magical. That is the point.
Magic is hard to debug.
The sharp claim avoids the lazy answer: “agent loops are hype.” That would be too easy and too false.
The sharper claim is that agent loops become real after the workflow becomes inspectable. The agent needs a narrow lane, an external critic, and permission to repeat. Loose rails magnify ambiguity. Tight rails turn the loop into a useful worker.
That is the uncomfortable middle ground. Builders who ignore loops will miss leverage. Builders who worship loops will manufacture cleanup work at machine speed.
The best current setup gives each role a boundary: human as governor, agent as executor, critic as boundary, and loop as compression.
The human keeps the map.
The agent takes the next hill.
A useful loop leaves a trail a senior engineer can audit: the patch it wrote, the review it answered, and the next change it made. That is why the Cursor -> GitHub -> Greptile example is more interesting than another autonomy demo. The artifacts are visible.
The cheap test is not whether the loop feels smart. It is whether the next human has less work.
Start with one workflow, one critic, one turn limit, and one named owner. Track three numbers: review minutes saved, defects caught before merge, and cleanup created after merge. A loop that improves the first two while shrinking the third earns another lane. A loop that expands cleanup gets shut off.
- Greg Isenberg, conversation with Ras Mic/Ross Mike, “WTF Is an ‘AI Agent Loop’? Genius or Hype?”, YouTube, June 9, 2026: https://www.youtube.com/watch?v=7clJ8IH784Q
- Anthropic, “Building effective agents,” December 19, 2024: https://www.anthropic.com/research/building-effective-agents
- OpenAI Agents SDK docs, agents and tracing: https://openai.github.io/openai-agents-python/agents/ and https://openai.github.io/openai-agents-python/tracing/
- LangChain docs, Human-in-the-Loop: https://docs.langchain.com/oss/python/langchain/frontend/human-in-the-loop
- Greptile developer quick reference: https://www.greptile.com/docs/developer-quick-reference